パナソニック 分電盤 大形リミッタースペース付 露出・半埋込両用形 1/10考验数据超过GPT-4o!清华等提议隐式流程奖励模子PRIME,在线刷SOTA
发布日期:2025-01-08 18:57 点击次数:182

随心数据墙パナソニック 分電盤 大形リミッタースペース付 露出・半埋込両用形,咱们还能作念些什么?

近日,来自清华UIUC等机构的究诘者提议了PRIME(Process Reinforcement through IMplicit REwards):通过隐式奖励来进行流程强化。

GitHub地址:https://github.com/PRIME-RL/PRIME
这是一种带有流程奖励的在线RL开源惩办决议,不错提高讲话模子的推理才气,超过了SFT(监督微调)随机蒸馏等法式。
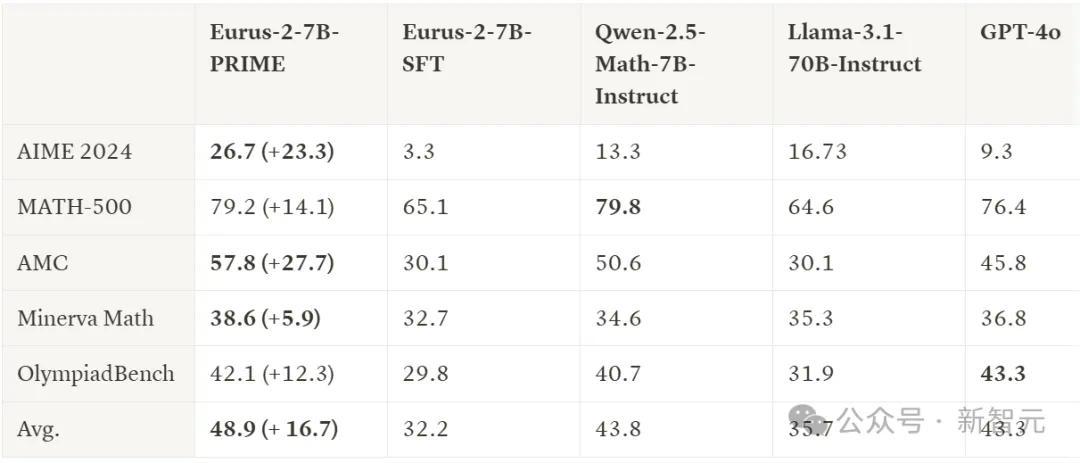
对比SFT,PRIME让模子在紧迫基准测试上竣事了浩大擢升:平均提高了16.7%,在AMC和AIME中王人提高了20%以上。
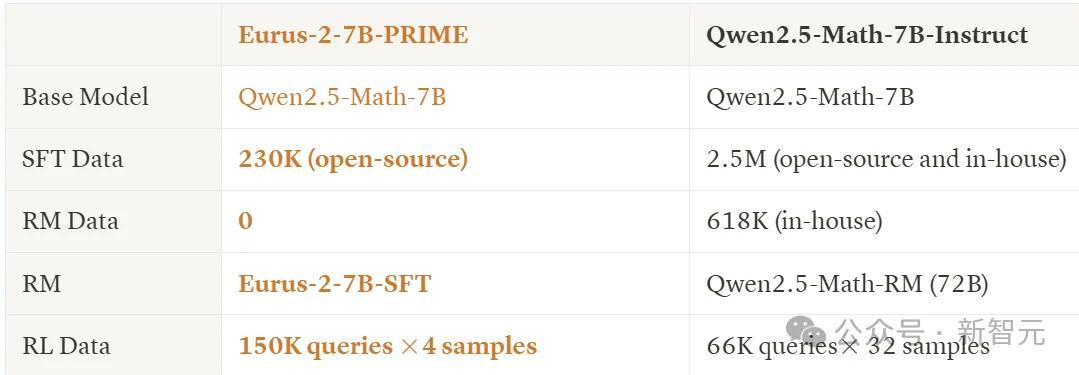
Eurus-2-7B-PRIME与Qwen2.5-Math-7B-Instruct,使用了疏浚的base model(Qwen-2.5-Math-7B),但在上表的6项测试中,5项王人超过了instruct版块,同期也超过了GPT-4o。
而这个获利只用了Qwen Math 1/10的数据资源(230K SFT + 150K RL)!
作家发布了本究诘中使用的统统模子和数据,感敬爱的读者请见文后贯穿。
1
流程奖励模子
淫淫色情网热身阶段(SFT)
如前所述,遴荐Qwen2.5-Math-7B-Base当作起先,然后上点难度,给与竞赛级别的数学和编程基准,包括AIME 2024、AMC、MATH-500、Minerva Math、OlympiadBench、LeetCode和LiveCodeBench(v2)。
起先对基础模子进行监督微调,以取得RL的初学模子(教模子学习某些推理花式)。
为此,究诘东说念主员打算了一个以动当作中心的链式推理框架,战术模子在每个关节中遴荐7个动作中的一个,并在扩展每个动作后住手。
为了构建SFT数据集,究诘者从几个开源数据纠书籍聚了推理指示。
值得预防的是,关于很多具有信得过谜底的数据集,作家遴荐将其保留用于之后的RL考验,主义是让SFT和RL使用不同的数据集,以使RL中的探索万般化,况且作家以为在PL中信得过标签愈加紧迫。
作家用LLaMA-3.1-70B-Instruct来回报指示,并使用系统领导条件模子扩展以动当作中心的想维链。
隐式PRM
底下接入流程奖励模子(PRM),这里给与隐式PRM,只需要在反映级别标签上考验ORM。
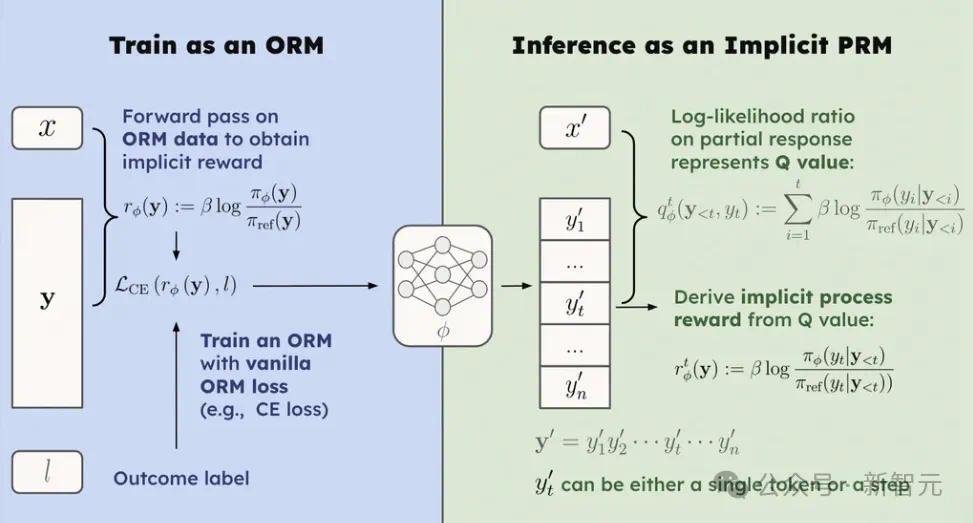
流程奖励模子粗浅相识即是对每个推理关节进行评分,举个例子:

PRM所以这种粒度来评价反映的。
在本文的隐式PRM中,不错使用以下表情免费取得流程奖励:
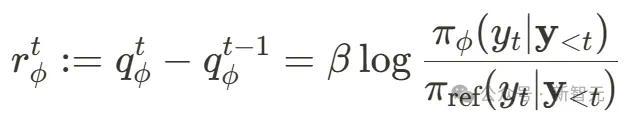
通过粗浅地集聚反映水平数据和考验ORM来取得PRM,而无需注视关节标签。
这与ORM考验主义的具体遴荐无关,比如使用交叉熵耗损来实例化隐式PRM,就不错替换成:
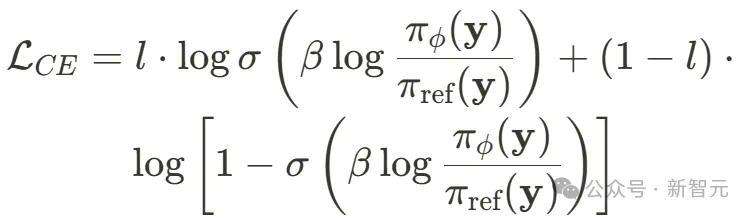
强化学习
本文的主义是世俗期骗强化学习(RL)来提高推理才气。针对这种资源有限的情况,作家讲究了一些最好试验:
从Ground Truth考证器和高质地数据入手:作家进行了严格的数据集聚和清算,以取得可考证的RL数据,并发现仅使用恶果考证器足以构建强劲的基线。
作家比较了不同的RL算法得出论断,无价值模子的REINFORCE类法式饱胀有用。
使用「mid-difficulty」问题进行褂讪考验:作家提议了一种名为在线领导过滤器的机制,通过过滤掉清贫和粗浅的问题,在很猛进度上褂讪了RL考验。
使用PRM进行强化学习
将PRM集成到在线强化学习中并非易事,这里有几个需要惩办的流毒挑战。
怎样为强化学习提供密集奖励?
奖励败落性一直是强化学习中持久存在的问题。到现在适度,咱们仍然莫得异常好的惩办决议来为LLM的在线强化学习构建密集奖励。
昔日的法式主如若为密集奖励建筑一个稀少的价值模子,无人不晓,这么的模子很难考验,而且性能擢升不大。
凭据前文对隐式PRM的先容,使用

不错免费从隐式PRM中取得token级别的流程奖励。
这种表情不错平直取代PPO中的价值模子,格外容易与任何上风意象函数和恶果奖励相衔尾。在试验中,作家将流程奖励与REINFORCE、RLOO、GRPO、ReMax和PPO集成在整个,并进行了轻浅的修改。
怎样配置一个好的PRM来启动RL?
即使咱们找到了在RL中使用流程奖励的阶梯,考验好的PRM也并非易事:需要集聚大限制(流程)奖励数据(很贵),况且模子应该在泛化和散播偏移之间取得精粹的均衡。
隐式PRM实质上是一种讲话模子。因此从表面上讲,不错使用任何讲话模子当作PRM。在试验中,作家发现当先的战术模子自己即是的一个很好的遴荐。
如安在线更新PRM以着重奖励黑客挫折?
在线RL中,幸免RM被过度优化或被黑客入侵至关紧迫,这需要RM与战术模子整个不断更新。联系词,鉴于关节标签的老本很高,在RL考验时辰很难更新PRM,——可扩展性和泛化问题。
可是,本文的隐式PRM仅条件更新恶果标签。也即是说,使用恶果考证器即可在考验时辰汗漫更新PRM。
此外,还不错进行双重转发:起先使用战术部署更新PRM,然后使用更新的PRM再行算计流程奖励,从而提供更准确的奖励估算。
PRIME算法
下图暗示PRIME算法的整个轮回:
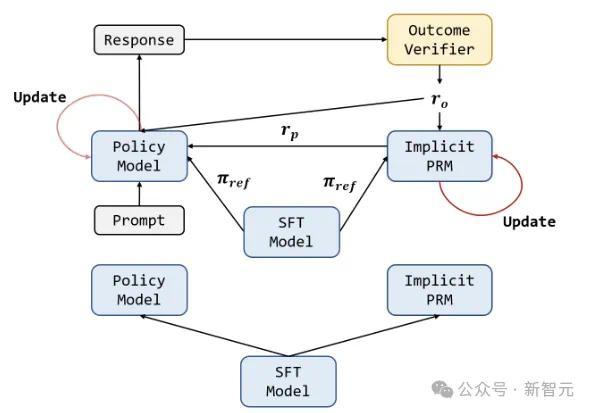
战术模子和PRM王人使用SFT模子进交运回荡。关于每个RL迭代,战术模子起先生成输出。然后,隐式PRM和恶果考证器对输出进行评分,隐式PRM在输出时通过恶果奖励进行更新。终末,将恶果奖励ro和流程奖励rp组合在整个,用于更新战术模子。
以下是算法的伪代码:

实验
默许情况下,使用SFT模子运回荡隐式PRM,并保留SFT模子当作参考对数探伤器。超参数方面,战术模子的学习率固定为5e-7,PRM学习率为1e-6,使用AdamW优化器,mini batchsize大小为256,micro batchsize为8。
rollout阶段集聚256个领导,每个领导采样4个反映。PRM考验时β=0.05,统统实验中将KL统统配置为0。
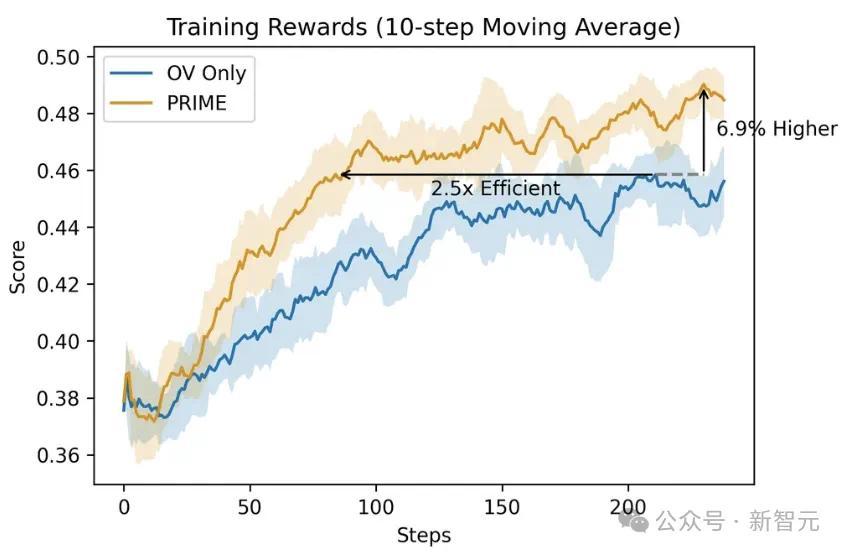
将PRIME与仅带有恶果考证器(OV)的RLOO进行比较,与败落奖励比拟,PRIME将RL考验加快了2.5倍,并将最终奖励提高了6.9%,且方差更低。不才游任务上,PRIME的性能也持久优于OV。
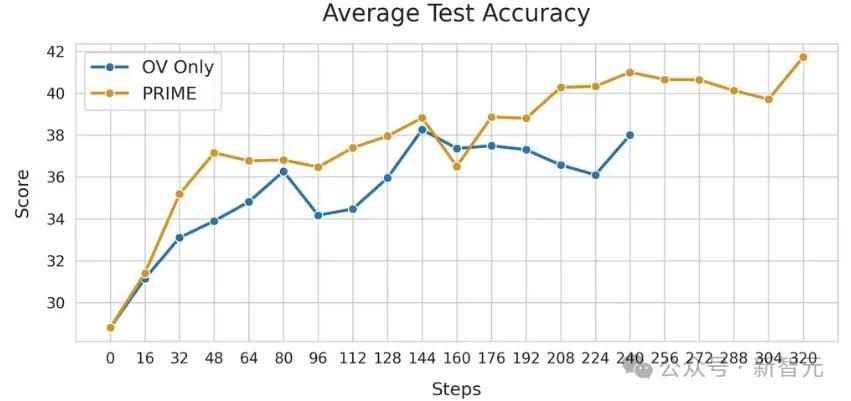
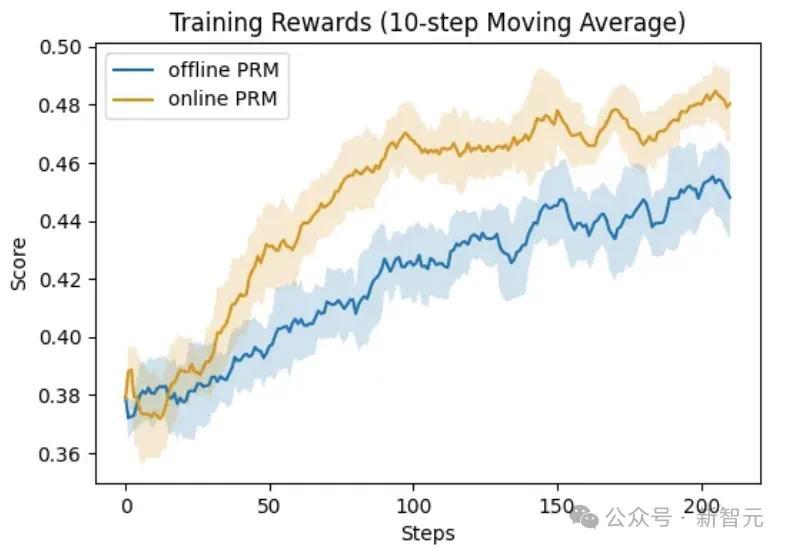
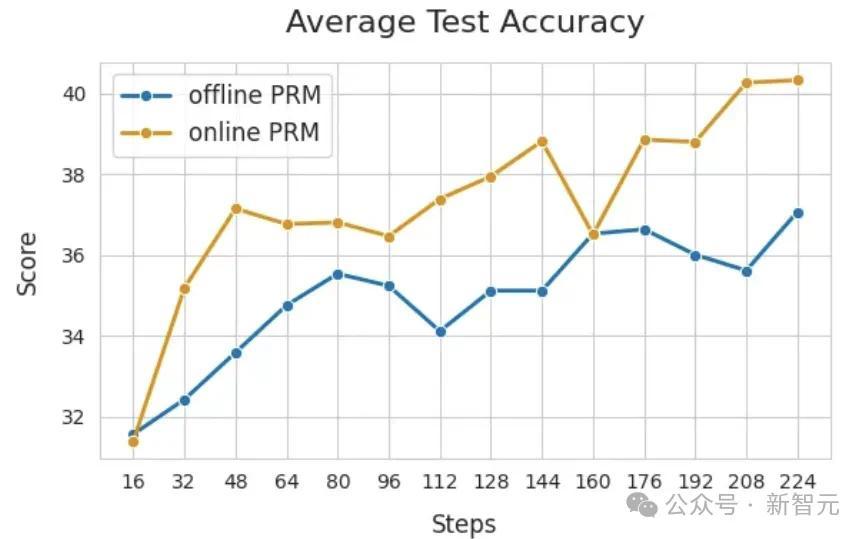
底下展示PRM在线更新的紧迫性。比较两种配置:在线PRM使用Eurus-2-7B-SFT运回荡,离线PRM使用EurusPRM-Stage1运回荡。
从下图中不错看出,在线PRM在考验集和测试集上的性能王人大大优于离线PRM。